Emacs 23 と Lookup
Emacs 23 and Lookup
Emacs 23
Emacs 23は、テキストエディタ Emacs の2009年7月にリリースされたバージョンです。本テキストエディタは特に漢字の編集に適した多くの優れた特徴を持っています。
- 文字コードはUCS(Unicode)・GB 18030のスーパーセットである22bitリニアなコード空間を持ちます。
- Unicode外の文字空間へは、JISの未定義部分などのマッピングを透過的に行えます。これによって古いrot47等のシーザー暗号や外字も扱えます。
- バイト列から文字へデコードする際に、文字プロパティを設定することができます。これを活用することで、統合漢字における日本・韓国・中国などの字形の違いを文字コードとは別で取り扱えます。
- UnicodeData 情報がエディタに組み込まれているため、正規化などの種々の処理を行えます。
- 文字の描画ルーチンは「フォントバックエンド」として切り離され、柔軟な拡張・変更が可能となっています。
- 拡張漢字B・Cの表示・編集が可能です(フォントバックエンドが対応している場合)。
- 異体字シーケンス(Ideographic Variation Sequence)による異体字表示が可能です(フォントバックエンドが対応している場合)。
Lookup
Lookupは、Emacsで様々な辞書を一括して検索することが可能なソフトウェアです。その最新版である Lookup 2.0では、Emacs 23の機能を生かし、拡張漢字などに対する検索に対応しています。
Lookupは、様々なフォーマットの辞書に対応していますが、漢字に関しては以下の商用・フリーな辞書やデータに対応しています。また、テキストベースのデータベースならば、検索インデックスの位置などを示す簡単なサポートファイルを準備することで、容易に検索対象として組み込めます。
- 広辞苑 (EPWING版) … 拡張漢字Cまでの範囲で、外字を実際のUCS漢字に変換して表示できます。
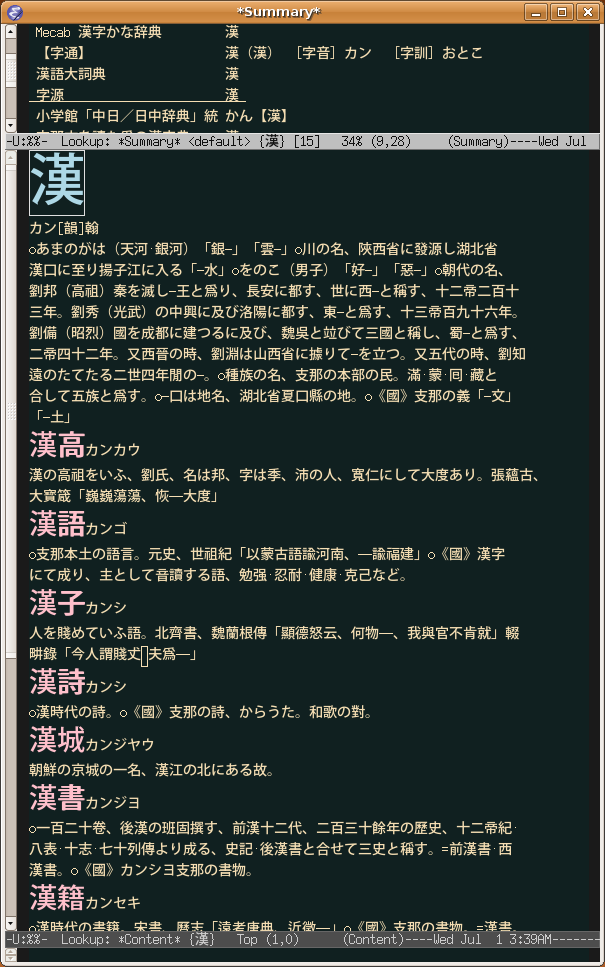
- 平凡社「字通」CD-ROM … 字通は「1点しんにょう」と「2点しんにょう」等の微細な違いを意図的に使い分けているため、LookupではIVSを使用してこれらの違いに追随しています。(lookupの字通のスクリーンショットでは、たとえば『萬物の化成』の「化成」の字にIVSを使用しています)。
- 小学館「中日/日中辞典」統合版 (EBXA-C版) … 従来は「ピンイン」および「ひらがな」でしか検索できませんでしたが、漢字インデックス付加ツールを使うと、日本漢字で検索できます。またLookupには、簡体字をピンインに直して本辞書で検索する機能があります。(lookupのスクリーンショット)
- 小学館「スーパー日本語大辞典」 … 漢字に関する豊富な情報が提供されています。EBStudioによってEPWINGに変換された辞書を扱うことができます。
- PDIC 中日辞書 … PDIC Unicode版に対応しているため、中日辞書などを使用することができます。(lookupのスクリーンショット)
- 角川・字源 … 角川「字源」(著作権切れ)XMLファイルに対して、親字および熟語で検索を行うことができます。(lookupのスクリーンショット)
- Unihan・康煕字典 … Unicode Consortiumで配布されている Unihan.txt に対して高速に検索を行うことができます。また、そのインデックス情報から、康煕字典のスキャン画像を参照することができます。
- 「支那文を讀む爲の漢字典」… 「青蛙亭」にて公開されているデータファイルに対して親字または読み方で検索し、そこからスキャンページを参照することができます。
- 「和製漢字の辞典」… 「和製漢字の辞典」にて公開されているHTMLファイルに対して、親字または読み方で検索し、表示可能です。和製漢字の辞典には現在、親字が2,700文字以上ありますが、そのうちUCSで符号化され、検索可能な漢字は1,100文字程度です。残りはIDSで検索できます。(lookupのスクリーンショット)
- 説文解字注・宋本廣韻・大漢和辞典 … 本漢字データベースで提供されているテキストやデータに対して、高速に検索を行うことができます。(lookupの説文解字注の検索のスクリーンショットと、宋本廣韻の検索のスクリーンショット)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
※ 現在の Lookup 2.0 は開発中のβ版であり、正式リリース時に上記の機能全てが必ずしも使用できるとは限らないことにご注意ください。
EmacsとIVS
Emacsは、使用するフォントバックエンドが「異体字シーケンス(IVS)」に対応している場合は、configure時に自動的にそれを検出します。EmacsがIVSに対応しているかどうかを調べたい場合は、configure時に生成される "config.h" の、 "HAVE_OTF_GET_VARIATION_GLYPHS" が "1" になっているかを確認してください。
Emacs が IVSに対応している場合は、IVS対応OpenTypeフォントを fontconfig のパスに入れてインストールしてください。OpenTypeフォントは、cmap14テーブルが入っていればIVSに対応しています。
IVS対応フォントをEmacsで使用するには、フォントをフォントセットに登録する必要があります。詳細は、Emacs Lisp リファレンスマニュアルを参照ください。以下は操作の一例です。
;; IVS対応フォント(ここでは小塚明朝 Pr6N)が、Emacsから見つかるかを確認します。
(find-font (font-spec :family "小塚明朝 Pr6N"))
→ <#font ....>
;; 現在のフレームで使用しているフォントセットで、小塚明朝を使用することを指示します。
;; 下記の例では、U+3400〜U+2FFFFの範囲の文字の表示に小塚明朝を優先して使用することを指示します。
(set-fontset-font nil '(#x3400 . #x2ffff) (font-spec :family "小塚明朝 Pr6N") nil 'prepend)
IVSの設定をした後、*scratch* バッファで(insert ?起 #xe0101) を実行してみてください。「起」の「己」が「巳」となっていれば、きちんとIVSが利用できています。
Lookupの「字通」サポートファイル `support-jitsuu.el' は、IVSを積極的に使用しています。IVSの効果を確認したい場合はこのファイルを参照してみてください。
EmacsとUnicodeの正規化
Unicodeでは、文字列を比較可能にするための前処理として「正規化」のアルゴリズムをUAX #15にて規定しています。
Unicodeの正規化アルゴリズムには NFD/NFC/NFKD/NFKC の4種類があります。これらのいずれも、正規化によって互換漢字は対応する統合漢字に置き換えられます。
漢字文字列の比較にあたっては、単なる正規化した文字列の比較では不十分な場合があります。また逆に、正規化において互換漢字の情報が喪失するのは不適切な場合があります。
互換漢字を維持する正規化として、Apple Macintosh のファイルシステム (HFS+) がファイル名などで使用する「修正NFD」があります。修正NFDの詳細はApple テクニカルレポート 1150にて述べられています。
Lookupに同梱(予定)されている `ucs-normalize.el' は、NFD/NFC/NFKD/NFKC および、この 修正NFD (HFS-NFD) とそれに対応する NFC (HFS-NFC) の実装が含まれています。Lookupには、SpotLight のEmacsインタフェース(`ndspotlight') がありますが、ndspotlight はこれを使用することで、日本語の濁音などの表示をHFS-NFCで行っています。(※ ucs-normalize.el は、バイトコンパイルしないと正常に動作しません。)
MacintoshでEmacsを使う場合は、default-file-name-coding-systemを、`ucs-normalize.el' で定義されている utf-8-hfs にすることで、`dired' 等で日本語を適切に表示し、またfind-file にて日本語ファイル名の自動検出等が可能になります。